Homework #1 - SQL
Overview
The first homework is to construct a set of SQL queries for analysing a dataset that will be provided to you. For this, you will look into the Northwind sample database. This homework is an opportunity to: (1) learn basic and certain advanced SQL features, and (2) get familiar with using a full-featured DBMS, SQLite, that can be useful for you in the future.
This is a single-person project that will be completed individually (i.e., no groups).
- Release Date: Sep 01, 2021
- Due Date: Sep 12, 2021 @ 11:59pm
Specification
The homework contains 10 questions in total and is graded out of 100 points. For each question, you will need to construct a SQL query that fetches the desired data from the SQLite DBMS. It will likely take you approximately 6-8 hours to complete the questions.
Placeholder Folder
Create the placeholder submission folder with the empty SQL files that you will use for each question:
$ mkdir placeholder $ cd placeholder $ touch q1_sample.sql\ q2_string_function.sql\ q3_northamerican.sql\ q4_delaypercent.sql\ q5_aggregates.sql\ q6_discontinued.sql\ q7_order_lags.sql\ q8_total_cost_quartiles.sql\ q9_youngblood.sql\ q10_christmas.sql $ cd ..
After filling in the queries, you can compress the folder by running the following command:
$ zip -j submission.zip placeholder/*.sql
The -j flag lets you compress all the SQL queries in the zip file without path information. The grading scripts will not work correctly unless you do this.
Instructions
Setting Up SQLite
You will first need to install SQLite on your development machine.
Make sure that you are using at least SQLite version 3.25! Older releases (prior to 2019) will not support the SQL features that you need to complete this assignment.
Install SQLite3 on Ubuntu Linux
Please follow the instructions.
Install SQLite3 on Mac OS X
On Mac OS Leopard or later, you don't have to! It comes pre-installed. You can upgrade it, if you absolutely need to, with Homebrew.
Load the Database Dump
-
Check if
sqlite3is properly working by following this tutorial. -
Download the database dump file:
$ wget https://15445.courses.cs.cmu.edu/fall2021/files/northwind-cmudb2021.db.gz
Check its MD5 checksum to ensure that you have correctly downloaded the file:
$ md5sum northwind-cmudb2021.db.gz f4fd955688d0dd9b5f4799d891f3f646 northwind-cmudb2021.db.gz
- Unzip the database from the provided database dump by running the following commands on your shell. Note that the database file be 31MB after you decompress it.
$ gunzip northwind-cmudb2021.db.gz $ sqlite3 northwind-cmudb2021.db
- Check the contents of the database by running the
.tablescommand on thesqlite3terminal. You should see fourteen tables, and the output should look like this:
$ sqlite3 northwind-cmudb2021.db SQLite version 3.31.1 Enter ".help" for usage hints. sqlite> .tables Category EmployeeTerritory Region Customer Order Shipper CustomerCustomerDemo OrderDetail Supplier CustomerDemographic Product Territory Employee ProductDetails_V
Check the schema
Get familiar with the schema (structure) of the tables (what attributes do they contain, what are the primary and foreign keys). Run the .schema $TABLE_NAME command on the sqlite3 terminal for each table. The output should look like the example below for each table.
Category
sqlite> .schema Category CREATE TABLE IF NOT EXISTS "Category" ( "Id" INTEGER PRIMARY KEY, "CategoryName" VARCHAR(8000) NULL, "Description" VARCHAR(8000) NULL );
Contains details for a category of goods. For example, this is a row from the table:
6|Meat/Poultry|Prepared meats
Customer
sqlite> .schema Customer CREATE TABLE IF NOT EXISTS "Customer" ( "Id" VARCHAR(8000) PRIMARY KEY, "CompanyName" VARCHAR(8000) NULL, "ContactName" VARCHAR(8000) NULL, "ContactTitle" VARCHAR(8000) NULL, "Address" VARCHAR(8000) NULL, "City" VARCHAR(8000) NULL, "Region" VARCHAR(8000) NULL, "PostalCode" VARCHAR(8000) NULL, "Country" VARCHAR(8000) NULL, "Phone" VARCHAR(8000) NULL, "Fax" VARCHAR(8000) NULL );
Contains details of a customer. For example, this is a row from the table:
LAMAI|La maison d'Asie|Annette Roulet|Sales Manager|...
For this assignment, we will not be using CustomerCustomerDemo or CustomerDemographic
Employee
sqlite> .schema Employee CREATE TABLE IF NOT EXISTS "Employee" ( "Id" INTEGER PRIMARY KEY, "LastName" VARCHAR(8000) NULL, "FirstName" VARCHAR(8000) NULL, "Title" VARCHAR(8000) NULL, "TitleOfCourtesy" VARCHAR(8000) NULL, "BirthDate" VARCHAR(8000) NULL, "HireDate" VARCHAR(8000) NULL, "Address" VARCHAR(8000) NULL, "City" VARCHAR(8000) NULL, "Region" VARCHAR(8000) NULL, "PostalCode" VARCHAR(8000) NULL, "Country" VARCHAR(8000) NULL, "HomePhone" VARCHAR(8000) NULL, "Extension" VARCHAR(8000) NULL, "Photo" BLOB NULL, "Notes" VARCHAR(8000) NULL, "ReportsTo" INTEGER NULL, "PhotoPath" VARCHAR(8000) NULL );
Contains information about employees. For example, this is a row from the table:
9|Dodsworth|Anne|Sales Representative|Ms.|1998-01-27...
Employee Territory
sqlite> .schema EmployeeTerritory CREATE TABLE IF NOT EXISTS "EmployeeTerritory" ( "Id" VARCHAR(8000) PRIMARY KEY, "EmployeeId" INTEGER NOT NULL, "TerritoryId" VARCHAR(8000) NULL );
Contains mappings between employees and which territories they are responsible for:
9/55113|9|55113
Order
sqlite> .schema Order CREATE TABLE IF NOT EXISTS "Order" ( "Id" INTEGER PRIMARY KEY, "CustomerId" VARCHAR(8000) NULL, "EmployeeId" INTEGER NOT NULL, "OrderDate" VARCHAR(8000) NULL, "RequiredDate" VARCHAR(8000) NULL, "ShippedDate" VARCHAR(8000) NULL, "ShipVia" INTEGER NULL, "Freight" DECIMAL NOT NULL, "ShipName" VARCHAR(8000) NULL, "ShipAddress" VARCHAR(8000) NULL, "ShipCity" VARCHAR(8000) NULL, "ShipRegion" VARCHAR(8000) NULL, "ShipPostalCode" VARCHAR(8000) NULL, "ShipCountry" VARCHAR(8000) NULL );
Contains information about orders. For example, this is a row from the table:
14321|OCEAN|9|2014-05-06 03:04:13|2014-05-26 07:17:05...
OrderDetail
sqlite> .schema OrderDetail CREATE TABLE IF NOT EXISTS "OrderDetail" ( "Id" VARCHAR(8000) PRIMARY KEY, "OrderId" INTEGER NOT NULL, "ProductId" INTEGER NOT NULL, "UnitPrice" DECIMAL NOT NULL, "Quantity" INTEGER NOT NULL, "Discount" DOUBLE NOT NULL );
Contains information about the individual products within an order. For example, this is a row from the table:
24255/33|24255|33|2.5|12|0.0
Product
sqlite> .schema Product CREATE TABLE IF NOT EXISTS "Product" ( "Id" INTEGER PRIMARY KEY, "ProductName" VARCHAR(8000) NULL, "SupplierId" INTEGER NOT NULL, "CategoryId" INTEGER NOT NULL, "QuantityPerUnit" VARCHAR(8000) NULL, "UnitPrice" DECIMAL NOT NULL, "UnitsInStock" INTEGER NOT NULL, "UnitsOnOrder" INTEGER NOT NULL, "ReorderLevel" INTEGER NOT NULL, "Discontinued" INTEGER NOT NULL );
Contains details for a product. For example, this is a row from the table:
66|Louisiana Hot Spiced Okra|2|2|24 - 8 oz jars|17|4|100|20|0
For this assignment, we will not be using ProductDetails_V
Region
sqlite> .schema Region CREATE TABLE IF NOT EXISTS "Region" ( "Id" INTEGER PRIMARY KEY, "RegionDescription" VARCHAR(8000) NULL );
Contains details for a region containing territories. For example, this is a row from the table:
4|Southern
Shipper
sqlite> .schema Shipper CREATE TABLE IF NOT EXISTS "Shipper" ( "Id" INTEGER PRIMARY KEY, "CompanyName" VARCHAR(8000) NULL, "Phone" VARCHAR(8000) NULL );
Contains details for a shipper referenced by an Order's ShipVia column.
For example, this is a row from the table:
2|United Package|(503) 555-3199
Supplier
sqlite> .schema Supplier CREATE TABLE IF NOT EXISTS "Supplier" ( "Id" INTEGER PRIMARY KEY, "CompanyName" VARCHAR(8000) NULL, "ContactName" VARCHAR(8000) NULL, "ContactTitle" VARCHAR(8000) NULL, "Address" VARCHAR(8000) NULL, "City" VARCHAR(8000) NULL, "Region" VARCHAR(8000) NULL, "PostalCode" VARCHAR(8000) NULL, "Country" VARCHAR(8000) NULL, "Phone" VARCHAR(8000) NULL, "Fax" VARCHAR(8000) NULL, "HomePage" VARCHAR(8000) NULL );
Contains details for a supplier of multiple products. For example, this is a row from the table:
16|Bigfoot Breweries|Cheryl Saylor|Regional Account Rep...
Territory
sqlite> .schema Territory CREATE TABLE IF NOT EXISTS "Territory" ( "Id" VARCHAR(8000) PRIMARY KEY, "TerritoryDescription" VARCHAR(8000) NULL, "RegionId" INTEGER NOT NULL );
Contains details for a territory served by an Employee.
For example, this is a row from the table:
90405|Santa Monica|2
Sanity Check
Count the number of rows in the Order table
sqlite> select count(*) from 'Order'; 16818
When referencing the Order table in your query,
make sure to use quotation marks around it ('Order').
This is because ORDER is a SQL keyword, and the parser will assume that you are
asking sqlite to order the query results.
The following figure illustrates the schema of these tables:
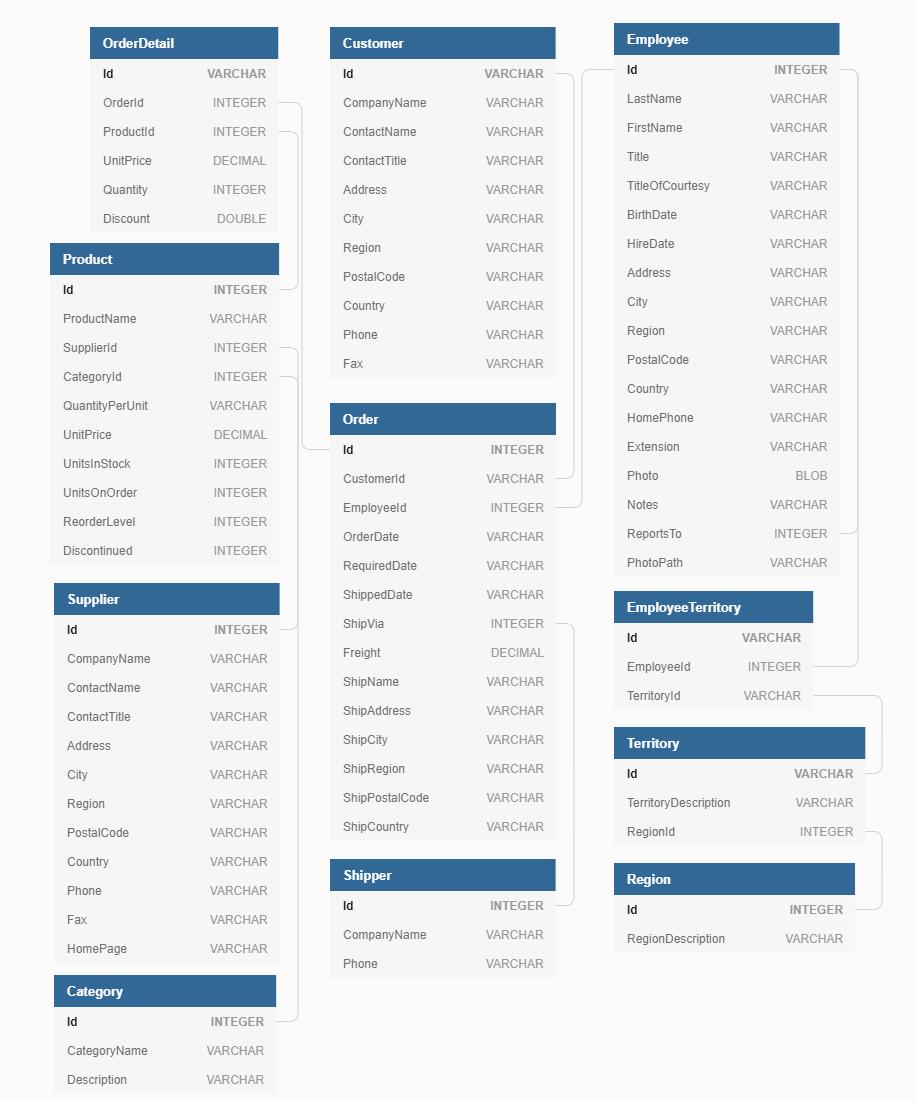
Construct the SQL Queries
Now, it's time to start constructing the SQL queries and put them into the placeholder files.
Q1 [0 points] (q1_sample):
The purpose of this query is to make sure that the formatting of your output matches exactly the formatting of our auto-grading script.Details: List all Category Names ordered alphabetically.
Answer: Here's the correct SQL query and expected output:
sqlite> SELECT CategoryName FROM Category ORDER BY CategoryName; Beverages Condiments Confections Dairy Products Grains/Cereals Meat/Poultry Produce SeafoodYou should put this SQL query into the appropriate file (
q1_sample.sql)
in the submission directory (placeholder).
Q2 [5 points] (q2_string_function):
Get all uniqueShipNames from the Order table that contain a hyphen '-'.
Details:
In addition, get all the characters preceding the (first) hyphen. Return ship names alphabetically.
Your first row should look like
Bottom-Dollar Markets|Bottom
Q3 [5 points] (q3_northamerican):
Indicate if an order'sShipCountry is in North America.
For our purposes, this is 'USA', 'Mexico', 'Canada'
Details:
You should print the Order Id, ShipCountry, and another column
that is either 'NorthAmerica' or 'OtherPlace' depending on the Ship Country.
Order by the primary key (Id) ascending and
return 20 rows starting from Order Id 15445
Your output should look like 15445|France|OtherPlace
or 15454|Canada|NorthAmerica
Q4 [10 points] (q4_delaypercent):
For eachShipper, find the percentage of orders which are late.
Details:
An order is considered late if ShippedDate > RequiredDate.
Print the following format, order by descending precentage, rounded
to the nearest hundredths, like United Package|23.44
Q5 [10 points] (q5_aggregates):
Compute some statistics about categories of productsDetails:
Get the number of products, average unit price (rounded to 2 decimal places),
minimum unit price, maximum unit price, and total units on order for
categories containing greater than 10 products.
Order by Category Id.
Your output should look like Beverages|12|37.98|4.5|263.5|60
Q6 [10 points] (q6_discontinued):
For each of the 8 discontinued products in the database, which customer made the first ever order for the product? Output the customer'sCompanyName and ContactName
Details:
Print the following format, order by ProductName alphabetically:
Alice Mutton|Consolidated Holdings|Elizabeth Brown
Q7 [15 points] (q7_order_lags):
For the first 10 orders byCutomerId BLONP: get the Order's
Id, OrderDate, previous OrderDate,
and difference between the previous and current.
Return results ordered by OrderDate (ascending)
Details:
The "previous" OrderDate for the first order should default to itself (lag time = 0).
Use the julianday() function for date arithmetic
(example).
Use lag(expr, offset, default)
for grabbing previous dates.
Please round the lag time to the nearest hundredth, formatted like
17361|2012-09-19 12:13:21|2012-09-18 22:37:15|0.57
Note: For more details on window functions, see here.
Q8 [15 points] (q8_total_cost_quartiles):
For eachCustomer, get the CompanyName, CustomerId, and "total expenditures".
Output the bottom quartile of Customers, as measured by total expenditures.
Details:
Calculate expenditure using UnitPrice and Quantity (ignore Discount).
Compute the quartiles for each company's total expenditures using
NTILE.
The bottom quartile is the 1st quartile, order them by increasing expenditure.
Make sure your output is formatted as follows (round expenditure to nearest hundredths):
Bon app|BONAP|4485708.49
Note:
There are orders for CustomerIds that don't appear in the Customer table.
You should still consider these "Customers" and output them.
If the CompanyName is missing, override the NULL to 'MISSING_NAME' using IFNULL.
Q9 [15 points] (q9_youngblood):
Find the youngest employee serving eachRegion. If a Region is not served by
an employee, ignore it.
Details:
Print the Region Description, First Name, Last Name, and Birth Date. Order by Region Id.
Your first row should look like
Eastern|Steven|Buchanan|1987-03-04
Q10 [15 points] (q10_christmas):
Concatenate theProductNames ordered by the
Company 'Queen Cozinha' on 2014-12-25.
Details:
Order the products by Id (ascending).
Print a single string containing all the dup names separated by commas like
Mishi Kobe Niku, NuNuCa Nuß-Nougat-Creme...
Hint: You might find Recursive CTEs useful.
Grading Rubric
Each submission will be graded based on whether the SQL queries fetch the expected sets of tuples from the database. Note that your SQL queries will be auto-graded by comparing their outputs (i.e. tuple sets) to the correct outputs. For your queries, the order of the output columns is important; their names are not.
Late Policy
See the late policy in the syllabus.
Submission
We use the Autograder from Gradescope for grading in order to provide you with immediate feedback. After completing the homework, you can submit your compressed folder submission.zip (only one file) to Gradescope:
Important: Use the Gradescope course code announced on Piazza.
We will be comparing the output files using a function similar to diff. You can submit your answers as many times as you like.
Collaboration Policy
- Every student has to work individually on this assignment.
- Students are allowed to discuss high-level details about the project with others.
- Students are not allowed to copy the contents of a white-board after a group meeting with other students.
- Students are not allowed to copy the solutions from another colleague.
WARNING: All of the code for this project must be your own. You may not copy source code from other students or other sources that you find on the web. Plagiarism will not be tolerated. See CMU's Policy on Academic Integrity for additional information.