Project #3 - Query Execution
Do not post your project on a public GitHub repository.
Overview
At this point in the semester, you have implemented many internal components of a database management system. In Project #1, you implemented a buffer pool manager. In Project #2, you implemented a hash table index. In this project, you will implement the components that allow BusTub to execute queries. You will create the operator executors that execute SQL queries and implement optimizer rules to transform query plans.
This project is composed of several tasks:
- Task #1: Access Method Executors
- Task #2: Aggregation and Join Executors
- Task #3: HashJoin Executor and Optimization
- Task #4: Sort + Limit Executors + Window Functions + Top-N Optimization
- Optional Leaderboard Task
This project must be completed individually (i.e., no groups).
Before starting, run git pull public master to pull the latest code from the public BusTub repo.
Project Road Map
This project is historically more complicated and involved compared to project 1 and project 2 (and/or other projects you may have encountered), since you will need to both understand and use multiple parts of existing bustub infrastructure. To ease this transition, this year we have provided a rough road map to guide your implementation.
Note: The following tasks are organized differently in the main writeup. This road map breaks the order of some tasks. You might opt to follow the road map, or you could just follow along the original tasks -- whichever works better for you!
Prep
Read the following background. As you read, play with bustub shell to understand:
- Use
explainorexplain (o)to show raw and optimized plans - Understand parameters in plan nodes (i.e. what the first and second 0 means in
#0.0) - Read a few simple plan node implementations in
include/execution/plans/ - Pay attention to various expression types in
include/execution/expressions/
Basic Executor Implementations
We suggest starting with the following executors in this order. 1. SeqScan, Insert, Update, Delete 2. NestedLoopJoin 3. Aggregation 4. Sort 5. Limit
Optimizer Rules and Remaining Executor Implementations
Before you begin, read some existing optimizer implementations provided in bustub. For each pair of optimizer rule and corresponding executor, we recommend reading the writeup portion for both before beginning implementation.
- Implement the
sort + limit -> top noptimizer rule and the TopN executor - Implement the
seq scan -> index scanoptimizer rule and the IndexScan executor - Implement the
nested loop join -> hash joinoptimizer rule and the HashJoin executor
Have (Fun) With Window Functions!
- Window Functions
Implement Some Leaderboard Tasks :)
- Start with Query 3 and Query 4
- Continue with Query 2: Too Many Joins!
- Continue with Query 1
Background: Query Processing
Please read this section carefully because you will need to construct your own SQL queries to test your executor implementation.
BusTub's architecture is as follows:

In the public BusTub repository, we provide a full query processing layer. You can use the BusTub shell to execute SQL queries, much like in other database systems. Use the following command to compile and run the BusTub shell:
cd build && make -j$(nproc) shell ./bin/bustub-shell
You can also use BusTub Web Shell to run the examples below. It is a complete reference solution of the system running in your browser!
Within the shell, you can use \dt to view all tables. By default, the BusTub shell will automatically create three tables that are pre-populated with data. This is provided as a convenience so that you do not need to load data every time you rebuild your solution. Changes to these tables will not be persisted when you restart the DBMS.
bustub> \dt +-----+----------------+------------------------------+ | oid | name | cols | +-----+----------------+------------------------------+ | 0 | __mock_table_1 | (colA:INTEGER, colB:INTEGER) | | 1 | __mock_table_2 | (colC:VARCHAR, colD:VARCHAR) | | 2 | __mock_table_3 | (colE:INTEGER, colF:VARCHAR) | | ... | ... | ... | +-----+----------------+------------------------------+
You can view all data from a table by using the SELECT statement:
bustub> SELECT * FROM __mock_table_1; +---------------------+---------------------+ | __mock_table_1.colA | __mock_table_1.colB | +---------------------+---------------------+ | 0 | 0 | | 1 | 100 | | 2 | 200 | | 3 | 300 | | 4 | 400 | | 5 | 500 | | ... | ... | +---------------------+---------------------+
Please note:
- BusTub only supports a small subset of SQL. Don't be surprised if it does not work with some SQL queries. For all SQL queries supported in BusTub, refer to the SQLLogicTest files in
tests/sql. - If you are using CLion to run the BusTub shell, please add a
--disable-ttyparameter to the shell, so that it works correctly in the CLion terminal. - Always end your statement with
;(except internal commands). - BusTub only supports
INTandVARCHAR(n)type. Also you should use single quotes for strings, e.g.,INSERT INTO table VALUES ('a').
Inspecting SQL Query Plans
BusTub supports the EXPLAIN command to print a query's execution plan. You can add EXPLAIN in front of any query. For example:
bustub> EXPLAIN SELECT * FROM __mock_table_1;
=== BINDER ===
BoundSelect {
table=BoundBaseTableRef { table=__mock_table_1, oid=0 },
columns=[__mock_table_1.colA, __mock_table_1.colB],
groupBy=[],
having=,
where=,
limit=,
offset=,
order_by=[],
is_distinct=false,
}
=== PLANNER ===
Projection { exprs=[#0.0, #0.1] } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
MockScan { table=__mock_table_1 } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
=== OPTIMIZER ===
MockScan { table=__mock_table_1 } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
The result of EXPLAIN provides an overview of the transformation process within the query processing layer. The statement is first processed by the parser and the binder, which produces an abstract syntax tree (AST) representing the query. In this example, the query is represented by a BoundSelect on __mock_table_1 that will retrieve two columns (colA and colB). Note that the binder automatically expands the * character from the original SQL query into the actual columns in the table.
Next, the binder AST is processed by the planner, which will produce an appropriate query plan. In this case, the query plan is a tree of two nodes, with data flowing from the leaves to the root:

After that, the optimizer will optimize the query plan. In this case, it removes the projection because it is redundant.
Let's consider a more complex example:
bustub> EXPLAIN (o) SELECT colA, MAX(colB) FROM
(SELECT * FROM __mock_table_1, __mock_table_3 WHERE colA = colE) GROUP BY colA;
=== OPTIMIZER ===
Agg { types=[max], aggregates=[#0.1], group_by=[#0.0] }
NestedLoopJoin { type=Inner, predicate=(#0.0=#1.0) }
MockScan { table=__mock_table_1 }
MockScan { table=__mock_table_3 }
For this example, the optimized query plan is:

In this project, you will need to construct SQL queries to test each of your executor's implementations. EXPLAIN is extremely helpful for you to know if a SQL query is using a specific executor.
Sample Executors
In the BusTub public repository, we provide several sample executor implementations.
Projection
A projection node can represent various computations on its input. It will always have exactly one child node. In the BusTub shell, inspect the query plans for the following queries:
EXPLAIN SELECT 1 + 2; EXPLAIN SELECT colA FROM __mock_table_1; EXPLAIN SELECT colA + colB AS a, 1 + 2 AS b FROM __mock_table_1;
A projection plan node consists of one or more expressions representing a computation:
ColumnValueExpression: directly places a column of the child executor to the output. The syntax#0.0means the first column in the first child. You will see something like#0.0 = #1.0in a plan for joins.ConstantExpression: represents a constant value (e.g.,1).ArithmeticExpression: a tree representing an arithmetic computation. For example,1 + 2would be represented by anArithmeticExpressionwith twoConstantExpression(1and2) as children.
Filter
A filter plan node is used to filter the output of a child given a predicate. For example:
EXPLAIN SELECT * FROM __mock_table_1 WHERE colA > 1;
A filter node has exactly one child and contains a predicate.
Values
A values plan node is used to directly produce values:
EXPLAIN values (1, 2, 'a'), (3, 4, 'b'); CREATE TABLE table1(v1 INT, v2 INT, v3 VARCHAR(128)); EXPLAIN INSERT INTO table1 VALUES (1, 2, 'a'), (3, 4, 'b');
Values plan nodes are useful when inserting user-supplied values into a table.
Query Plan Syntax
As you might have noticed, EXPLAIN produces a string of column descriptions after each plan node. That's the output schema of the node. Consider this example output:
Projection { exprs=[#0.0, #0.1] } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
This indicates that the executor representing this plan node will produce two columns, both of integer types. The output schema is inferred within the planner. For this project, your executor implementations must produce tuples with schema exactly as specified in the plan node, or they will fail our unit tests.
Project Specification
In this project, you will add new operator executors and query optimizations to BusTub. BusTub uses the iterator (i.e., Volcano) query processing model, in which every executor implements a Next function to get the next tuple result. When the DBMS invokes an executor's Next function, the executor returns either (1) a single tuple or (2) an indicator that there are no more tuples. With this approach, each executor implements a loop that continues calling Next on its children to retrieve tuples and process them one by one.
In BusTub's implementation of the iterator model, the Next function for each executor returns a record identifier (RID) in addition to a tuple. A record identifier serves as a unique identifier for the tuple.
The executors are created from an execution plan in executor_factory.cpp.
All test cases in this project are written in a special file format called SQLLogicTest (derived from SQLite). You can find how to use it at the end of this page.
Task #1 - Access Method Executors
In the background section above, we saw that the BusTub can already retrieve data from mock tables in SELECT queries. This is implemented without real tables by using a MockScan executor to always generate the same tuples using a predefined algorithm. This is why you cannot update these tables.
In this task, you will implement executors that read from and write to tables in the storage system. You will complete your implementation in the following files:
- src/include/execution/seq_scan_executor.h
- src/execution/seq_scan_executor.cpp
- src/include/execution/insert_executor.h
- src/execution/insert_executor.cpp
- src/include/execution/update_executor.h
- src/execution/update_executor.cpp
- src/include/execution/delete_executor.h
- src/execution/delete_executor.cpp
- src/include/execution/index_scan_executor.h
- src/execution/index_scan_executor.cpp
- src/optimizer/seqscan_as_indexscan.cpp
Each of these executors is described below.
SeqScan
The SeqScanPlanNode can be planned with a SELECT * FROM table statement.
bustub> CREATE TABLE t1(v1 INT, v2 VARCHAR(100));
Table created with id = 15
bustub> EXPLAIN (o,s) SELECT * FROM t1;
=== OPTIMIZER ===
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:VARCHAR)
The SeqScanExecutor iterates over a table and returns its tuples one at a time.
Hint: Make sure that you understand the difference between the pre-increment and post-increment operators when using the TableIterator object. You might get strange output if you confuse ++iter with iter++. (Check here for a quick refresher.)
Hint: Do not emit tuples that are deleted in the TableHeap.
Check the is_deleted_ field of the corresponding TupleMeta for each tuple.
Hint: The output of sequential scan is a copy of each matched tuple and its original record identifier (RID).
Note: BusTub does not support DROP TABLE or DROP INDEX. You can reset your database by restarting the shell.
Insert
The InsertPlanNode can be planned with a INSERT statement. Note that you will need to use a single quote to specify a VARCHAR value.
bustub> EXPLAIN (o,s) INSERT INTO t1 VALUES (1, 'a'), (2, 'b');
=== OPTIMIZER ===
Insert { table_oid=15 } | (__bustub_internal.insert_rows:INTEGER)
Values { rows=2 } | (__values#0.0:INTEGER, __values#0.1:VARCHAR)
The InsertExecutor inserts tuples into a table and updates any affected indexes. It has exactly one child producing values to be inserted into the table. The planner will ensure that the values have the same schema as the table. The executor will produce a single tuple of integer type as the output, indicating how many rows have been inserted into the table. Remember to update indexes when inserting into the table, if there are indexes associated with it.
Hint: See the System Catalog section below for information about the system catalog. To initialize this executor, you will need to look up information about the table being inserted into.
Hint: See the Index Updates section below for further details about updating a table's indexes.
Hint: You will need to use the TableHeap class to perform table modifications.
Hint: You only need to change the is_delete_ field when creating or modifying TupleMeta. For the insertion_txn_ and the deletion_txn_ fields, just set it to INVALID_TXN_ID. These fields are intended to be used in future semesters where we might switch to an MVCC storage.
Update
The UpdatePlanNode can be planned with an UPDATE statement. It has exactly one child with the records to be updated in the table.
bustub> explain (o,s) update test_1 set colB = 15445;
=== OPTIMIZER ===
Update { table_oid=20, target_exprs=[#0.0, 15445, #0.2, #0.3] } | (__bustub_internal.update_rows:INTEGER)
SeqScan { table=test_1 } | (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
The UpdateExecutor modifies existing tuples in a specified table. The executor will produce a single tuple of integer type as the output, indicating how many rows have been updated. Remember to update any indexes affected by the updates.
Hint: To implement an update, first delete the affected tuple and then insert a new tuple. Do not use the TableHeap UpdateTupleInplaceUnsafe function unless you are implementing leaderboard optimizations for project 4.
Delete
The DeletePlanNode can be planned with a DELETE statement. It has exactly one child with the records to be deleted from the table. Your delete executor should produce an integer output that represents the number of rows that it deleted from the table. It will also need to update any affected indexes.
bustub> EXPLAIN (o,s) DELETE FROM t1;
=== OPTIMIZER ===
Delete { table_oid=15 } | (__bustub_internal.delete_rows:INTEGER)
Filter { predicate=true } | (t1.v1:INTEGER, t1.v2:VARCHAR)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:VARCHAR)
bustub> EXPLAIN (o,s) DELETE FROM t1 where v1 = 1;
=== OPTIMIZER ===
Delete { table_oid=15 } | (__bustub_internal.delete_rows:INTEGER)
Filter { predicate=#0.0=1 } | (t1.v1:INTEGER, t1.v2:VARCHAR)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:VARCHAR)
You may assume that the DeleteExecutor is always at the root of the query plan in which it appears. The DeleteExecutor should not modify its result set.
Hint: To delete a tuple, you need to get a RID from the child executor and update the is_deleted_ field of the corresponding TupleMeta for that tuple.
IndexScan
The IndexScanExecutor does point lookup using the hash index to retrieve RIDs for tuples. The operator then uses these RIDs to retrieve their tuples in the corresponding table. It then emits these tuples one at a time. The executor should be able to support several point lookups on the same index.
You can test your index scan executor by SELECT FROM <table> WHERE <index column> = <val>. You will implement the optimizer rule to transform a SeqScan into an IndexScan in the next section.
bustub> CREATE TABLE t1(v1 int, v2 int);
Table created with id = 22
bustub> CREATE INDEX t1v1 ON t1(v1);
Index created with id = 0
bustub> EXPLAIN (o,s) SELECT * FROM t1 WHERE v1 = 1;
=== OPTIMIZER ===
IndexScan { index_oid=0, filter=(#0.0=1) } | (t1.v1:INTEGER, t1.v2:INTEGER)
The type of the index object in the plan will always be HashTableIndexForTwoIntegerColumn in this project. You can safely cast it and store it in the executor object:
htable_ = dynamic_cast<HashTableIndexForTwoIntegerColumn *>(index_info_->index_.get())
You can then do point lookup with the hash index, lookup the tuples from the table heap, and emit the satisfying tuple according to the predicate. BusTub only supports indexes with a single, unique integer column. Our test cases will not contain duplicate keys. Hence, this executor returns one tuple per point lookup if it exists.
You will need to finish the optimizer rule in the next section to transform a SeqScan into an IndexScan. It may make more sense to implement the optimizer rule before implementing IndexScan to understand the kind of queries IndexScanExecutor will need to support.
Hint: We will never insert duplicate rows into tables with indexes.
Hint: As above, do not emit tuples that are deleted.
Optimizing SeqScan to IndexScan
As we learned in lecture, when we are querying on the indexed column, using an IndexScan will significantly boost the lookup performance. To this end, we need to push down the filter into the scanner so that we know the key to lookup in the index. Then we can directly retrieve the value over the index, instead of doing a full table scan or index scan.
You would need to modify the optimizer to transform a SeqScanPlanNode into a IndexScanPlanNode when it is possible.
Consider the following example:
bustub> EXPLAIN (o) SELECT * FROM t1 WHERE v1 = 1;
Without applying the MergeFilterScan and the SeqScan as IndexScan optimizer rule, the plan may look like the following:
Filter { predicate=(#0.0=1) } | (t1.v1:INTEGER, t1.v2:INTEGER, t1.v3:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER, t1.v3:INTEGER)
After applying the MergeFilterScan and SeqScan as IndexScan optimizer rule, we can just do a quick index lookup instead of iterating the entire table. The resulting plan will look like the following:
IndexScan { index_oid=0, filter=(#0.0=1) } | (t1.v1:INTEGER, t1.v2:INTEGER, t1.v3:INTEGER)
Here's the brief steps to implement this optimizer rule:
-
Enable Predicate pushdown to SeqScan: We can implement a predicate filter in SeqScanExecutor so that later the index scan node will have the predicate. We've already enabled MergeFilterScan optimizer rule merge_filter_scan.cpp in the starter optimizer rules for you.
-
Use Index: You can check the filtering columns from the predicate. If there happens to exist an index on this column, create an IndexScanPlanNode. Note that to get full score, you will need to support this optimizer rule in a few different situations: (1) when there's one equality test on the indexed column in predicate (i.e.,
WHERE v1 = 1) (2) when the indexed column ordering is flipped (i.e.,WHERE 1 = v1) and (3) when there are several point lookups on the same index (i.e.,WHERE v1 = 1 or v1 = 4). Note that queries of the formSELECT * FROM t1 WHERE v1 = 1 AND v2 = 2should still use a seq scan, thus you do not need to split the predicates.
Please check Optimizer Rule Implementation Guide section for details on implementing an optimizer rule.
Now that you have implemented all storage related executors. In the following tasks, you can create tables and insert some values by yourself to test your own executor implementation! At this point, you should also have passed SQLLogicTests #1 to #6.
Hint: You may find the utility ExtendibleHashTableIndex::ScanKey function helpful.
Hint: Think about how to handle queries of the form WHERE v1 = 1 OR v1 = 1. It may help to view AggregateKey in /src/include/execution/plans/aggregation_plan.h.
Task #2 - Aggregation & Join Executors
You will complete your implementation in the following files:
- src/include/execution/aggregation_executor.h
- src/execution/aggregation_executor.cpp
- src/include/execution/nested_loop_join_executor.h
- src/execution/nested_loop_join_executor.cpp
Aggregation
The AggregationPlanNode is used to support queries like the following:
EXPLAIN SELECT colA, MIN(colB) FROM __mock_table_1 GROUP BY colA; EXPLAIN SELECT COUNT(colA), min(colB) FROM __mock_table_1; EXPLAIN SELECT colA, MIN(colB) FROM __mock_table_1 GROUP BY colA HAVING MAX(colB) > 10; EXPLAIN SELECT DISTINCT colA, colB FROM __mock_table_1;
The aggregation executor computes an aggregation function for each group of input. It has exactly one child. The output schema consists of the group-by columns followed by the aggregation columns.
As discussed in class, a common strategy for implementing aggregation is to use a hash table, with the group-by columns as the key. In this project, you may assume that the aggregation hash table fits in memory. This means that you do not need to implement a multi-stage, partition-based strategy, and the hash table does not need to be backed by buffer pool pages.
We provide a SimpleAggregationHashTable data structure that exposes an in-memory hash table (std::unordered_map) but with an interface designed for computing aggregations. This class also exposes an SimpleAggregationHashTable::Iterator type that can be used to iterate through the hash table. You will need to complete the CombineAggregateValues function for this class.
The aggregation executor itself will not need to handle the HAVING predicate. The planner will plan aggregations with a HAVING clause as an AggregationPlanNode followed by a FilterPlanNode.
Hint: In the context of a query plan, aggregations are pipeline breakers. This may influence the way that you use the AggregationExecutor::Init() and AggregationExecutor::Next() functions in your implementation. Carefully decide whether the build phase of the aggregation should be performed in AggregationExecutor::Init() or AggregationExecutor::Next().
Hint: You must handle NULL values in the input of the aggregation functions (i.e., a tuple may have a NULL value for the attribute used in the aggregation function). See test cases for expected behavior. Group-by columns will never be NULL.
Hint: When performing aggregation on an empty table, CountStarAggregate should return zero and all other aggregate types should return integer_null. This is why GenerateInitialAggregateValue initializes most aggregate values as NULL.
NestedLoopJoin
The DBMS will use NestedLoopJoinPlanNode for all join operations, by default. Consider the following example queries:
EXPLAIN SELECT * FROM __mock_table_1, __mock_table_3 WHERE colA = colE; EXPLAIN SELECT * FROM __mock_table_1 INNER JOIN __mock_table_3 ON colA = colE; EXPLAIN SELECT * FROM __mock_table_1 LEFT OUTER JOIN __mock_table_3 ON colA = colE;
You will need to implement an inner join and left join for the NestedLoopJoinExecutor using the simple nested loop join algorithm from class. The output schema of this operator is all columns from the left table followed by all columns from the right table.
For each tuple in the outer table, consider each tuple in the inner table and emit an output tuple if the join predicate is satisfied.
We will provide all test cases on Gradescope AS-IS. We will not test with strange edge cases involving NULLs (such as NULLs in the group-by clause or in indexes). At this point, you should pass SQLLogicTests - #7 to #12.
Hint: You should use the predicate in the NestedLoopJoinPlanNode. See AbstractExpression::EvaluateJoin, which handles the left tuple and right tuple and their respective schemas. Note that this returns a Value, which could be false, true, or NULL. See FilterExecutor for how to apply predicates on tuples.
Task #3 - HashJoin Executor and Optimization
You will complete your implementation in the following files:
- src/include/execution/hash_join_executor.h
- src/execution/hash_join_executor.cpp
- src/optimizer/nlj_as_hash_join.cpp
You need to implement NestedLoopJoinExecutor in Task #2 before starting this task.
HashJoin
The DBMS can use HashJoinPlanNode if a query contains a join with a conjunction of several equi-conditions between two columns (equi-conditions are seperated by AND). Consider the following example queries:
EXPLAIN SELECT * FROM __mock_table_1, __mock_table_3 WHERE colA = colE; EXPLAIN SELECT * FROM __mock_table_1 INNER JOIN __mock_table_3 ON colA = colE; EXPLAIN SELECT * FROM __mock_table_1 LEFT OUTER JOIN __mock_table_3 ON colA = colE; EXPLAIN SELECT * FROM test_1 t1, test_2 t2 WHERE t1.colA = t2.colA AND t1.colB = t2.colC; EXPLAIN SELECT * FROM test_1 t1 INNER JOIN test_2 t2 on t1.colA = t2.colA AND t2.colC = t1.colB; EXPLAIN SELECT * FROM test_1 t1 LEFT OUTER JOIN test_2 t2 on t2.colA = t1.colA AND t2.colC = t1.colB;
You will need to implement the inner join and left join for HashJoinExecutor using the hash join algorithm from class. The output schema of this operator is all columns from the left table followed by all columns from the right table. As with aggregation, you may assume that the hash table used by the join fits entirely in memory.
Your implementation should correctly handle the case where multiple tuples have hash collisions (on either side of the join). You will want to make use of the join key accessors functions GetLeftJoinKey() and GetRightJoinKey() in the HashJoinPlanNode to construct the join keys for the left and right sides of the join, respectively.
Hint: You will need a way to hash a tuple with multiple attributes in order to construct a unique key. As a starting point, take a look at how the SimpleAggregationHashTable in the AggregationExecutor implements this functionality.
Hint: As with aggregation, the build side of a hash join is a pipeline breaker. You should again consider whether the build phase of the hash join should be performed in HashJoinExecutor::Init() or HashJoinExecutor::Next().
Optimizing NestedLoopJoin to HashJoin
Hash joins usually yield better performance than nested loop joins.
You should modify the optimizer to transform a NestedLoopJoinPlanNode into a HashJoinPlanNode when it is possible to use a hash join. Specifically, the hash join algorithm can be used when a join predicate is a conjunction of several equi-conditions between two columns. For this project, you should be able to handle a varying number of equi-conditions connected by AND.
Consider the following example:
bustub> EXPLAIN (o) SELECT * FROM test_1 t1, test_2 t2 WHERE t1.colA = t2.colA AND t1.colB = t2.colC;
Without applying the NLJAsHashJoin optimizer rule, the plan may look like:
NestedLoopJoin { type=Inner, predicate=((#0.0=#1.0)and(#0.1=#1.2)) }
SeqScan { table=test_1 }
SeqScan { table=test_2 }
After applying the NLJAsHashJoin optimizer rule, the left and right join key expressions will be extracted from the single
join predicate in the NestedLoopJoinPlanNode. The resulting plan will look like:
HashJoin { type=Inner, left_key=[#0.0, #0.1], right_key=[#0.0, #0.2] }
SeqScan { table=test_1 }
SeqScan { table=test_2 }
Please check the Optimizer Rule Implementation Guide section for details on implementing an optimizer rule. At this point, you should pass SQLLogicTests - #14 to #15.
Hint: Make sure to check which table the column belongs to for each side of the equi-condition. It is possible that the column from outer table is on the right side of the equi-condition. You may find ColumnValueExpression::GetTupleIdx helpful.
Hint: The order to apply optimizer rules matters. For example, you want to optimize NestedLoopJoin into HashJoin after filters and NestedLoopJoin have merged.
Hint When dealing with multiple equi-conditions, try to extract out the keys recursively, instead of matching the joining condition with multiple layers of if clauses.
Task #4: Sort + Limit Executors + Window Functions + Top-N Optimization
You will complete your implementation in the following files:
- src/include/execution/sort_executor.h
- src/execution/sort_executor.cpp
- src/include/execution/limit_executor.h
- src/execution/limit_executor.cpp
- src/include/execution/topn_executor.h
- src/execution/topn_executor.cpp
- src/include/execution/window_function_executor.h
- src/execution/window_function_executor.cpp
- src/optimizer/sort_limit_as_topn.cpp
You need to implement IndexScanExecutor in Task #1 before starting this task. If there is an index over a table, the query processing layer will automatically pick it for sorting. In other cases, you will need a special sort executor to do this.
For all ORDER BY clauses, we assume every sort key will only appear once. You do not need to worry about ties in sorting.
Sort
Except in the case that the ORDER BY attributes matches the keys of an index, BusTub will use a SortPlanNode for all ORDER BY operators.
EXPLAIN SELECT * FROM __mock_table_1 ORDER BY colA ASC, colB DESC;
This plan node does not change schema (i.e., the output schema is the same as the input schema). You can extract sort keys from order_bys, and then use std::sort with a custom comparator to sort all tuples from the child. You can assume that all entries in a table can fit in memory.
If the query does not include a sort direction in the ORDER BY clause (i.e., ASC, DESC), then the sort mode will be default (which is ASC).
Limit
The LimitPlanNode specifies the number of tuples that query will generate. Consider the following example:
EXPLAIN SELECT * FROM __mock_table_1 LIMIT 10;
The LimitExecutor constrains the number of output tuples from its child executor. If the number of tuples produced by its child executor is less than the limit specified in the plan node, this executor has no effect and yields all of the tuples that it receives.
This plan node does not change schema (i.e., the output schema is the same as the input schema). You do not need to support offsets.
Top-N Optimization Rule
For this last task, you are going to modify BusTub's optimizer to support converting top-N queries. Consider the following query:
EXPLAIN SELECT * FROM __mock_table_1 ORDER BY colA LIMIT 10;
By default, BusTub will execute this query by (1) sort all data from the table (2) get the first 10 elements. This is obviously inefficient, since the query only needs the smallest values. A smarter way of doing this is to dynamically keep track of the smallest 10 elements so far. This is what the BusTub's TopNExecutor does.
You will need to modify the optimizer to support converting a query with ORDER BY + LIMIT clauses to use the TopNExecutor. See OptimizeSortLimitAsTopN for more information.
An example of the optimized plan of this query:
TopN { n=10, order_bys=[(Default, #0.0)]} | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
MockScan { table=__mock_table_1 } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
Please check Optimizer Rule Implementation Guide section for details on implementing an optimizer rule. At this point, your implementation should be able to pass SQLLogicTests #16 to #19. Integration-test-2 requires you to use release mode to run.
Hint: Think of what data structure can be used to track the top n elements (Andy mentioned it in the lecture). The struct should hold at most k elements (where k is the number specified in LIMIT clause).
Window Functions
In general, window functions have three parts: partition by, order by, and window frames. All three are optional, so multiple combinations of these features make the window function daunting at first. However, the conceptual model for a window function helps make it easier to understand. The conceptual model is the following: * Split the data based on the conditions in the partition by clause. * Then, in each partition, sort by the order by clause. * Then, in each partition (now sorted), iterate over each tuple. For each tuple, we compute the boundary condition for the frame for that tuple. Each frame has a start and end (specified by the window frame clause). The window function is computed on the tuples in each frame, and we output what we have computed in each frame.
The diagram below shows the general execution model of the window function.
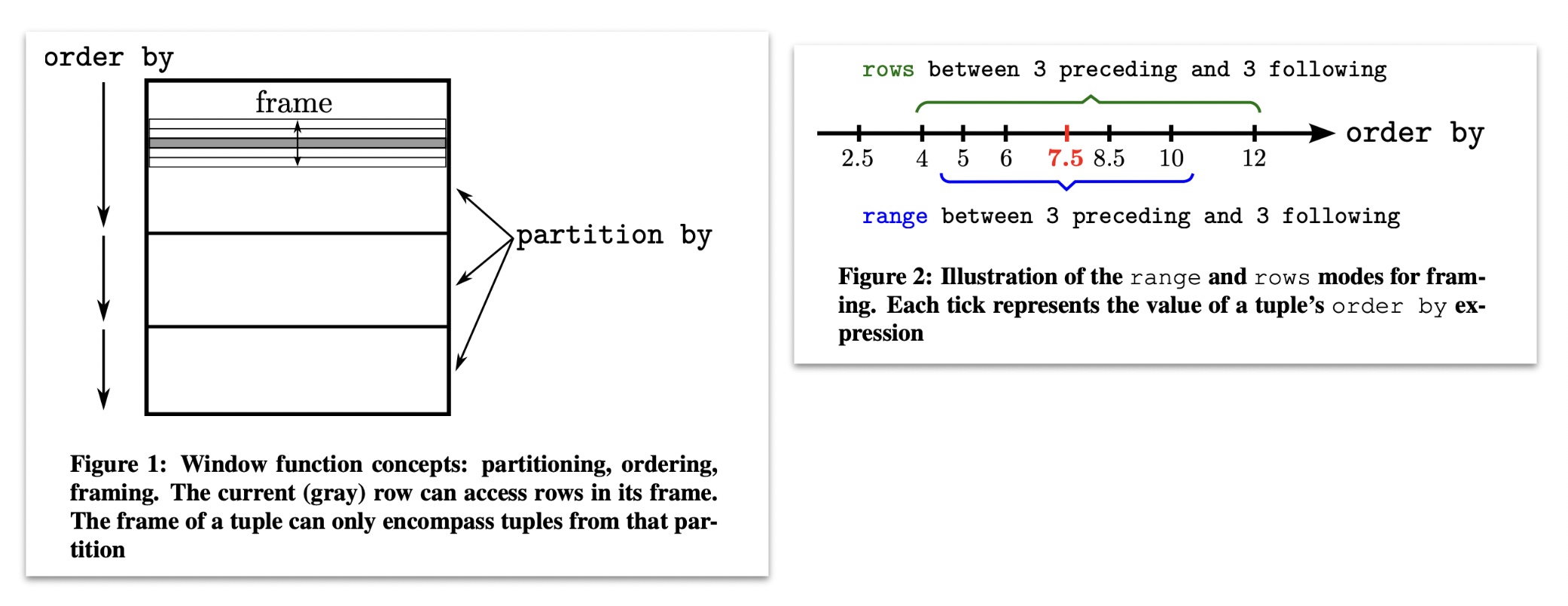
Let's dive deeper with a few examples using the following table:
CREATE TABLE t (user_name VARCHAR(1), dept_name VARCHAR(16), salary INT);
INSERT INTO t VALUES ('a', 'dept1', 100);
INSERT INTO t VALUES ('b', 'dept1', 200);
INSERT INTO t VALUES ('c', 'dept1', 300);
INSERT INTO t VALUES ('e', 'dept2', 100);
INSERT INTO t VALUES ('d', 'dept2', 50);
INSERT INTO t VALUES ('f', 'dept2', 60);
Example #1 The below example calculates a moving average of the salary for each department. You can consider it as first sort the rows for each partition by name and then calculate the average of the row before the current row, current row and the row after current row.
bustub> SELECT user_name, dept_name, AVG(salary) OVER \ (PARTITION BY dept_name ORDER BY user_name ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) \ FROM t; +-----------+-----------+-----------------------------+ | user_name | dept_name | salary | +-----------+-----------+-----------------------------+ | a | dept1 | 150 | | b | dept1 | 200 | | c | dept1 | 250 | | d | dept2 | 75 | | e | dept2 | 70 | | f | dept2 | 80 | +-----------+-----------+-----------------------------+
Example #2 The query below calculates a moving average of the salary for each department. Different from previous example, when window frames are omitted and order by clauses not omitted, it calculates from the first row to the current row for each partition.
bustub> SELECT user_name, dept_name, AVG(salary) OVER (PARTITION BY dept_name ORDER BY user_name) FROM t; +-----------+-----------+-----------------------------+ | user_name | dept_name | salary | +-----------+-----------+-----------------------------+ | a | dept1 | 100 | | b | dept1 | 150 | | c | dept1 | 200 | | d | dept2 | 50 | | e | dept2 | 75 | | f | dept2 | 70 | +-----------+-----------+-----------------------------+
Example #3 This query show that when order by and window frames are both omitted, it calculates from the first row to the last row for each partition, which means the results within the partition should be the same.
bustub> SELECT user_name, dept_name,AVG(salary) OVER (PARTITION BY dept_name) FROM t; +-----------+-----------+-----------------------------+ | user_name | dept_name | salary | +-----------+-----------+-----------------------------+ | a | dept1 | 200 | | b | dept1 | 200 | | c | dept1 | 200 | | e | dept2 | 70 | | d | dept2 | 70 | | f | dept2 | 70 | +-----------+-----------+-----------------------------+
bustub> SELECT user_name, dept_name, AVG(salary) OVER () FROM t; +-----------+-----------+-----------------------------+ | user_name | dept_name | salary | +-----------+-----------+-----------------------------+ | a | dept1 | 135 | | b | dept1 | 135 | | c | dept1 | 135 | | e | dept2 | 135 | | d | dept2 | 135 | | f | dept2 | 135 | +-----------+-----------+-----------------------------+
For this task, you do not need to handle window frames. As in the above examples, you only need to implement PARTITION BY and ORDER BY clauses. You may notice that the ORDER BY clauses also change the order of non-window function columns. This is not necessary as the output order is not guaranteed and depends on the implementation. For simplicity, BusTub ensures that all window functions within a query have the same ORDER BY clauses. This means the following queries are not supported in BusTub and your implementation does not need to handle them:
SELECT SUM(v1) OVER (ORDER BY v1), SUM(v1) OVER (ORDER BY v2) FROM t1; SELECT SUM(v1) OVER (ORDER BY v1), SUM(v2) OVER () FROM t1;
The test case will not check the order of output rows as long as columns within each row are matched. Therefore, you can sort the tuples first before doing the calculations when there are ORDER BY clauses, and do not change the order of tuples coming from the child executor when there are no order by clauses.
You can implement the executor in the following steps:
- Sort the tuples as indicated in
ORDER BY. - Generate the initial value for each partition
- Combine values for each partition and record the value for each row.
You may reuse the code from sort executors to complete step 1 and the code from aggregation executor to complete step 2 and step 3.
Apart from aggregation functions implemented in previous tasks, you will need to implement RANK as well. The BusTub planner ensures that ORDER BY clause is not empty if RANK window function is present. Be aware that there might be ties and please refer to test cases for the expected behavior.
Optional Leaderboard Tasks
For this project's leaderboard challenge, you should implement new executors and optimizer rules to make the system execute the following queries as fast as possible.
These tasks are optional. You do not need to complete them to get a perfect score on the project. Unlike previous projects, segfaults and timeouts in project 3 leaderboard tests will not affect your score.
It is possible that your implementation will produce different results for existing queries after implementing the leaderboard optimizations. We require you to pass all tests after implementing new optimization rules. We will also force using starter rules for some test cases. For example, in order to ensure your index scan executor works, we force the starter rule in this sqllogictest file with set force_optimizer_starter_rule=yes.
Query 1: Do we really need window function?
Consider the following sample database:
CREATE TABLE t1(x INT, y INT, z INT);
Now a user comes along and executes the following query.
SELECT x, y FROM ( SELECT x, y, rank() OVER (partition by x order by y) as rank FROM t1 ) WHERE rank <= 3;
Recommended Optimizations: Optimize the window plan node into a group-by top-n. You may want to implement TopNPerGroupPlan and TopNPerGroupExecutor. Also notice if it contains multiple rows having the same rank, return all the rows which have rank <= 3.
Query 2: Too Many Joins!
Consider the following sample database:
CREATE TABLE t4(x int, y int); CREATE TABLE t5(x int, y int); CREATE TABLE t6(x int, y int);
The user is not from CMU and they are writing terrible SQL. They forgot how write queries with joins so they puts all predicates in the WHERE clause.
SELECT * FROM t4, t5, t6
WHERE (t4.x = t5.x) AND (t5.y = t6.y) AND (t4.y >= 1000000)
AND (t4.y < 1500000) AND (t6.x >= 100000) AND (t6.x < 150000);
Recommended Optimizations: Decompose the filter condition to extract hash join keys, and push down the remaining filter conditions to be below the hash join.
Query 3: The Mad Data Scientist
There is a data scientist invested all their money in NFTs. After realizing their terrible mistake, they go crazy and starts writing some weird SQL queries. Consider the following example:
SELECT v, d1, d2 FROM (
SELECT v,
MAX(v1) AS d1, MIN(v1), MAX(v2), MIN(v2),
MAX(v1) + MIN(v1), MAX(v2) + MIN(v2),
MAX(v1) + MAX(v1) + MAX(v2) AS d2
FROM t7 LEFT JOIN (SELECT v4 FROM t8 WHERE 1 == 2) ON v < v4
GROUP BY v
)
(This is not the same as the actual leaderboard query; refer to the test file.)
Recommended Optimizations:
- Column pruning – you only need to compute v, d1, d2 from the left table in aggregation. We've provided a skeleton file
column_pruning.cpp. - Common expression elimination, transform always false filter to dummy scan (values plan node of zero rows)
- Some more if you could think of :)
Hint: You do not need to implement a complete rule for optimizing these queries. (1) a complete predicate pushdown requires you to handle all plan nodes – limit, order by, etc. But to optimize for Q2, you only need to implement push down predicates over hash join / nested loop joins. (2) a complete join reordering requires you to handle predicates correctly (and maybe absorb filters in-between back to the join predicate), and you do not need to do that. Just make your optimizer work with those queries is enough.
Query 4: All that work, for nothing?
After all the hard work with Q1 to Q3, here's something short and sweet. Imagine you have the following 2 tables representing everyone alive in the 1950s, and everyone born in the 1600s. Someone with no concept of human lifespan (or a firm belief in vampires) tries to construct a query that outputs the intersection of the 2 tables. You know the result will be empty, but your join executors won't, what can you do to help speed up the process?
SELECT * FROM alive_in_1950s a INNER JOIN born_in_1600s b ON a.birthday = b.birthday
(This is not the same as the actual leaderboard query; refer to the test file.)
Recommended Optimizations: Bloom filter for the hash table used during the build phase of the hash join.
Leaderboard Policy
- Submissions with leaderboard bonus are subject to manual review by TAs.
- By saying "review", it means that TAs will manually look into your code, or if they are unsure whether an optimization is correct or not by looking, they will make simple modification to existing test cases to see if your leaderboard optimization correctly handled the specific cases that you want to optimize.
- One example of simple modification: change the buffer pool manager size for the benchmark.
- Your optimization should not affect correctness. You can optimize for specific cases, but it should work for all inputs in your optimized cases.
- Allowed: only handling 3-table join reordering in Fall 2022 project 3.
- Allowed: optimize for leaf node size > 100 in project 2.
- Disallowed: compare the plan with the leaderboard test and convert it to ValueExecutor with the output table in project 3. That’s because your optimization should work for all table contents. Hardcoding the answer will yield wrong result in some cases.
- You should not try detecting whether your submission is running leaderboard test by using side information.
- Unless we allow you to do so.
- Disallowed: use
#ifdef NDEBUG, etc.
- Submissions with obvious correctness issues will not be assigned leaderboard bonus.
- You cannot use late days for leaderboard tests.
- If you are unsure about whether an optimization is reasonable, you should post on Piazza or visit any TA's office hour.
Additional Information
This section provides some additional information on other system components in BusTub that you will need to interact in order to complete this project.
System Catalog
A database maintains an internal catalog to keep track of meta-data about the database. In this project, you will interact with the system catalog to query information regarding tables, indexes, and their schemas.
The entirety of the catalog implementation is in src/include/catalog/catalog.h. You should pay particular attention to the member functions Catalog::GetTable() and Catalog::GetIndex(). You will use these functions in the implementation of your executors to query the catalog for tables and indexes.
Index Updates
For the table modification executors (InsertExecutor, UpdateExecutor, and DeleteExecutor) you must modify all indexes for the table targeted by the operation. You may find the Catalog::GetTableIndexes() function useful for querying all of the indexes defined for a particular table. Once you have the IndexInfo instance for each of the table's indexes, you can invoke index modification operations on the underlying index structure.
In this project, we use your implementation of hash table index from Project #2 as the underlying data structure for all index operations. Therefore, successful completion of this project relies on a working implementation of the hash tables.
Optimizer Rule Implementation Guide
The BusTub optimizer is a rule-based optimizer. Most optimizer rules construct optimized plans in a bottom-up way. Because the query plan has this tree structure, before applying the optimizer rules to the current plan node, you want to first recursively apply the rules to its children.
At each plan node, you should determine if the source plan structure matches the one you are trying to optimize, and then check the attributes in that plan to see if it can be optimized into the target optimized plan structure.
In the public BusTub repository, we already provide the implementation of several optimizer rules. Please take a look at them as reference.
Instructions
See the Project #0 instructions for how to create your private repository and set up your development environment.
You must pull the latest changes from the upstream BusTub repository for test files and other supplementary files we provide in this project.
Testing
We will use SQLLogicTest to perform testing and benchmarking. To use it,
make -j$(nproc) sqllogictest ./bin/bustub-sqllogictest ../test/sql/p3.00-primer.slt --verbose
You can use the bustub-sqllogictest program to run slt files. Remember to recompile sqllogictest before doing any testing. In this project, we provide ALL test cases to you. There are no hidden tests. The test cases are located at test/sql/.
Memory Leaks
For this project, we use LLVM Address Sanitizer (ASAN) and Leak Sanitizer (LSAN) to check for memory errors. To enable ASAN and LSAN, configure CMake in debug mode and run tests as you normally would. If there is memory error, you will see a memory error report. Note that macOS only supports address sanitizer without leak sanitizer.
In some cases, address sanitizer might affect the usability of the debugger. In this case, you might need to disable all sanitizers by configuring the CMake project with:
$ cmake -DCMAKE_BUILD_TYPE=Debug -DBUSTUB_SANITIZER= ..
Development Hints
You can use BUSTUB_ASSERT for assertions in debug mode. Note that the statements within BUSTUB_ASSERT will NOT be executed in release mode.
If you have something to assert in all cases, use BUSTUB_ENSURE instead.
We encourage you to use a graphical debugger to debug your project if you are having problems.
If you are having compilation problems, running make clean does not completely reset the compilation process. You will need to delete your build directory and run cmake .. again before you rerun make.
Post all of your questions about this project on Piazza. Do not email the TAs directly with questions.
Grading Rubric
Each project submission will be graded based on the following criteria:
- Does the submission successfully execute all of the test cases and produce the correct answer?
- Does the submission execute without any memory leaks?
Late Policy
See the late policy in the syllabus.
Submission
After completing the assignment, submit your implementation to Gradescope for evaluation.
Running make submit-p3 in your build/ directory will generate a zip archive called project3-submission.zip under your project root directory that you can submit to Gradescope.
Remember to resolve all style issues before submitting:
make format make check-clang-tidy-p3
Collaboration Policy
- Every student has to work individually on this assignment.
- Students are allowed to discuss high-level details about the project with others.
- Students are not allowed to copy the contents of a white-board after a group meeting with other students.
- Students are not allowed to copy the solutions from another colleague.
WARNING: All of the code for this project must be your own. You may not copy source code from other students or other sources that you find on the web. Plagiarism will not be tolerated. See CMU's Policy on Academic Integrity for additional information.